Search History:
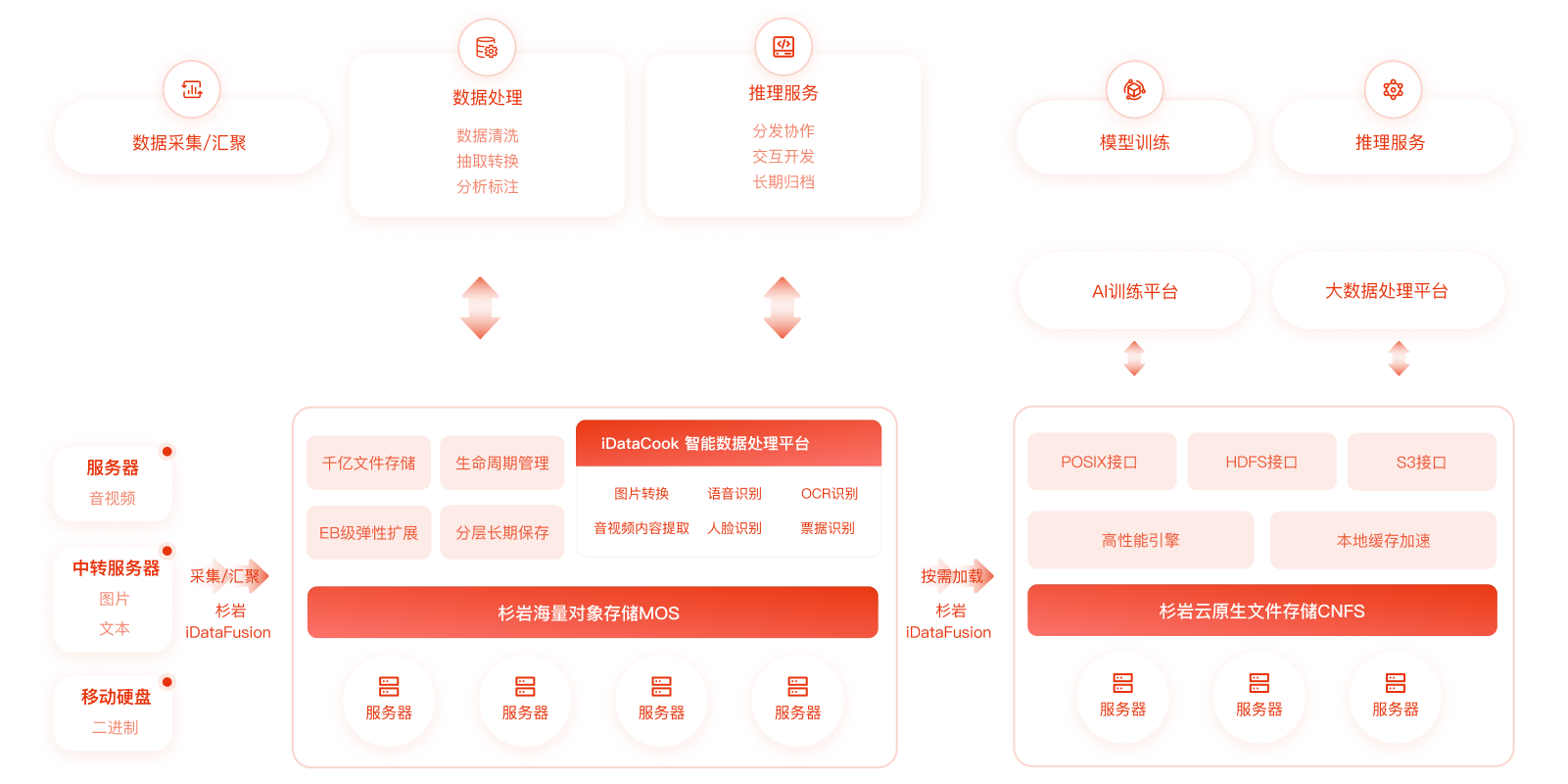
Data Storage
Addressing storage issues in different storage scenarios and data formats
MOS
HotMassive data
unstructured
object storage
USP
Block/File/Object
High Reliability
Private Cloud
CNFS
AI training
machine learning
big data analytics
Data Management
Provide efficient, intelligent, and reliable data management solutions
iDataFusion
Data collection
Migration and replication
Conversion processing
iDataExplorer
Efficient retrieval
Online annotation
Data analysis
CMS
Unified monitoring
Unified configuration
Unified management
Data Application
Quick retrieval and invocation of business, enabling data to unleash greater value
IDM
HotQuality traceability
Efficient retrieval
Reduced TCO
iDataCook
Format conversion
OCR recognition
Online annotation



-
 Industry Solutions
Industry Solutions
-
 General Solutions
General Solutions