《杉岩两语》企业级Ceph之路(三):关于Ceph产品化的一些感悟
发布于2019-09-05
此文为Ceph中国社区年终盛典上杉岩数据CTO邱尚高所分享的内容,字字干货:

一 、装修
前阵子家里装修,刚好楼下热情、好客的邻居是做铝合金家具工厂的,新型家具材料,给了些样品,即使是我这种外行,也会真心觉得材质确实好,当然,价格也基本是出厂价,比建材市场更是便宜非常多。所以,橱柜的装修就这么定下来了。
但在具体订做的过程中,还是发生了几件恼人的事情:
首先,工厂没有橱柜的设计,邻居自己也忙,需要我提供设计图纸,而且绘图他也没人,只会看。我只能捡起大学所学的机械制图,花了大半天功夫画了张图给他。
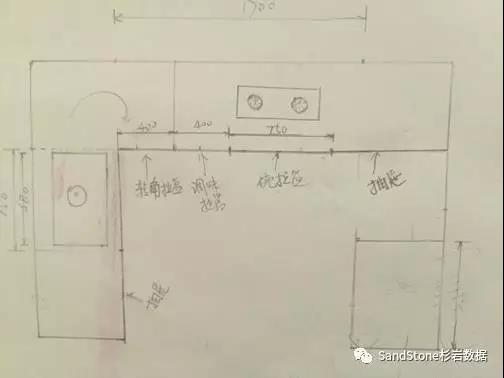
其次,因为不够专业,所以没有考虑到瓷砖/地板对尺寸的影响,导致安装时问题不断。比如房间门装矮了,厕所门没考虑瓷砖厚度,导致装不进去等等…
现在回想起这件事,我的邻居当然是没有错的,原因其实在于这个过程中缺少一个很重要的 东西。而这个东西,也是三年来杉岩在基于Ceph实现产品化过程中,我们和用户同样遇到的。
二 、感悟
Ceph作为一款十年历史的开源分布式产品,其稳定性、可用性确实得到业界的普遍认可。2014年我们基于Ceph给用户提供的一个管理系统,到目前为止仅出现了两次问题,其中一次是硬件问题,一次是使用方式不当的问题。作为一个开源产品,能够有如此高的稳定性和可用性,这应该就是Ceph能够获得今天的成绩的首要原因。
关于Ceph的优势,这里简单概括如下:
对各种异常考虑的比较完善, 比如网络抖动、去中心化的心跳机制、恢复机制对复杂异常的考虑;
很少因为代码问题导致程序coredump,也没有出现过内存泄漏问题,说明代码质量还是不错的;
高级功能比较全面,支持块、对象、文件,同时支持副本、EC、tier、scrub等高级特性;
不过,“好的产品优点相似,不好的产品缺点却各有各的不同”,我们今天和你分享的更多的就是这些不同。随着我们服务的企业客户的不断增加, Ceph真正应用于企业客户不同场景中所遇到的各种问题也逐步开始暴露。
采用Ceph替代传统SAN的烦恼
在2014年到2015年上半年的时候,杉岩利用Ceph主要给客户提供一些替代IP SAN的解决方案,客户希望利用Ceph的高扩展性、高可靠性提供一个相对规模较大,性价比较好的通用存储池,降低一些数据量较大、低价值数据的存储成本。这时,就遇到了各种问题:
1、不支持标准的块接口
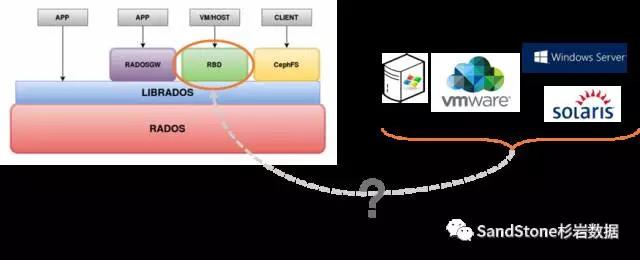
Ceph称提供块接口,但其实它的块接口之支持Qemu-KVM,并不是一个传统的SCSI标准块接口,是无法直接应用于VMware、Windows和Solaris等系统的。这些系统对接的块存储都是类似于FC SAN或者IP SAN这种提供标准SCSI接口的设备。将Ceph推向这些传统的企业应用是无法实现对接的。
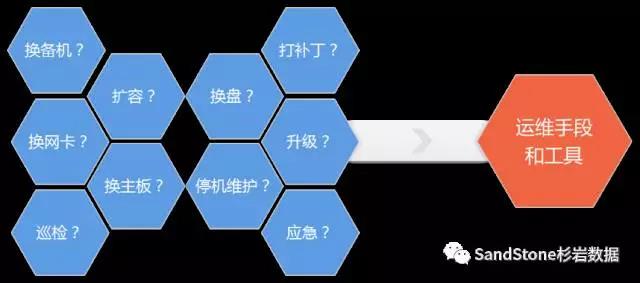
2、运维管理手段和工具缺乏
这个问题是Ceph目前直接应用于企业客户最大的问题,易用性和易维护性,SageWeil在今年也提出易用性是未来Ceph的重要改进方向。杉岩在应用与企业客户中遇到各种问题,然后不断完善产品,其中最典型的问题就是各种硬件备件的更换。
在使用传统存储时,当硬件部件出现问题时,企业的IT运维人员希望尽快更换配件,避免出现更加严重的问题,为此一些企业都有的备件库,当硬件配件出现问题时,运维人员通过更换配置做简单的操作就可以完成配件的更换。而如果直接使用Ceph,则可能要面临敲一堆的命令才能完成更换的操作,这是Ceph直接作为企业产品无法接受的。
3、无法实现数据卷的安全隔离需求
传统的企业存储是一个公共资源,上面运行着多种业务应用,为了防止不同业务应用读取或者破坏非自身业务应用的数据,传统企业存储通过LUN MASKING/CHAP 协议等,实现存储卷的安全隔离。
而Ceph设计用于云平台,所有的RBD对于云平台的每个主机都是可见可操作的,从而实现虚拟机在整个集群的迁移。所以需要一套在Ceph之上实现一套类似于LUN MASKING的机制,保证不同业务只能看到和访问分配给自己的存储卷。

4、混合盘性能无法发挥
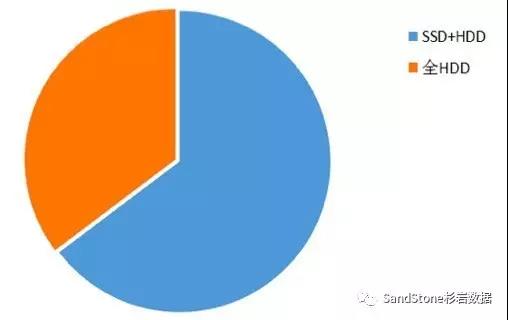
另外,我们发现,目前在云数据中心,客户更多的还是采用SSD+HDD的混合模式,有部分对性能无要求的客户采用了纯HDD的模式,采用全SSD的客户目前还没有实际遇到(有部分客户做过测试)。
在SSD+HDD混合模式下,Ceph遇到的烦恼是对SSD写带宽消耗过大。大家都知道SSD性能很高,这是对于随机小IO来说,但SATA SSD的顺序写MBPS其实并不高,如下图是Intel DC S3520的顺序写性能,最大也就380MBPS。一个好一些的SAS盘,写带宽都可以到300MBPS,SATA盘至少也有150MBPS的性能。
一般来说客户的一个存储节点采用1-2个SSD作为缓存盘,对外提供的带宽其实也就300MBPS到600MBPS,而Ceph的journal + 两副本的方式,消耗了4倍写带宽,最终实际一个服务器能提供的写带宽只有75MBPS~150MPBS,远远小于多个机械盘的顺序写能力,严重制约着Ceph的顺序写性能。

Intel DC S3520 固态盘性能
Ceph应用在VMware超融合的烦恼
随着应用客户的不断增加,我们发现, Ceph主要的应用场景是虚拟化场景,占80%以上,其中VMware又占到了50%以上,而且应用VMware的大部分都是超融合环境。

而此时遇到的主要问题包括:
1、对更好的iSCSI并发能力的需求
在替代IP SAN模式下,不同应用主机之间一般使用LUN比较独立。可以通过LUN归属的方式,不同的LUN通过不同的单个iSCSI Target提供出来,即可实现较好的并发。
但在VMware环境下,一般只划分很少的LUN(一般1-2个大LUN),供整个VMWare集群共享使用。如果此时依然采用LUN归属的方式,单个iSCSI Target将成为整个集群的瓶颈点。在这种场景下,iSCSI必须实现的是一个全Active的架构,保证LUN在所有的target上可以同时访问,从而保证任何一个iSCSI Target不会成为性能的瓶颈点。

2、必须支持VAAI
VMWare实现VAAI接口,在虚拟机批量创建、克隆,读写性能上影响非常大。比如在不支持VAAI的XCOPY时,SandStone跟FC SAN的克隆性能相差10倍。企业客户一对比,就觉得存储性能太差。在企业私有云环境,批量克隆虚拟机确实是一个常见的运维操作,过慢确实也影响到客户的使用效率。
3、CPU消耗过大严重影响性能发挥
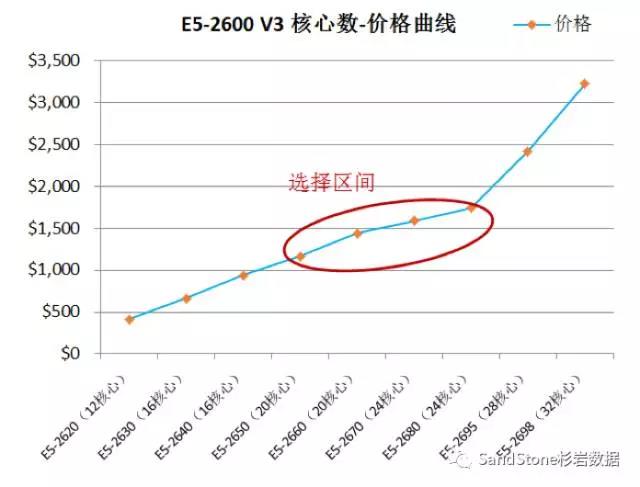
Ceph的CPU消耗较高是众所周知的,当分离部署时这个问题还不明显,一旦应用于VMware超融合场景,问题就暴露的比较明显了。因为在超融合环境下,虚拟机需要占用大量的CPU资源,而CPU的核心在一定范围内价格是可控的,但超过一定核心数价格会变得非常高。下图是E5-2600系列CPU的核心数(逻辑核)与价格的对应曲线(价格数据取自中关村在线),一般客户主要选择2路E5-2650 – E5-2680的CPU,最大逻辑核心也就24个,往往能分配给存储的CPU基本只有8-12个逻辑核。
杉岩最初的优化版本必须在16个核心才能返回出两个Intel DC 3500 SSD的能力,经过一段时间的优化,最终能够在8-10个逻辑CPU核把两个SSD的能力发挥出来。
三 、进展
经过三年坚持不懈的研发投入以及千百次的用户现场测试、使用、调优......杉岩正在同每一个致力于Ceph的企业和个人一道将Ceph打磨成一款可以适应于企业客户的多种场景的企业级产品。Ceph不仅仅是一行行看上去很美丽的开源代码。
应用场景 | 问题 | 当前状态 |
替代SAN(非超融合) | 高性能的标准iSCSI接口 | 只增加了0.1毫秒时延 |
运维管理 | 提供了丰富的管理功能 | |
SSD带宽消耗优化 | 带宽消耗降低一半 | |
数据安全与权限管理 | 支持LUN Masking/CHAP等特性 | |
超融合(VMWare) | 深度优化的VAAI | OSD对VAAI接口的原生支持 |
更低的CPU资源消耗 | 8逻辑核心发挥出2个SSD的性能 | |
分布式iSCSI 机头 | 支持全分布式iSCSI Targets |
未来,杉岩将秉承“来源社区、贡献社区”的态度,逐步将在CEPH上取得的一些成绩回馈给社区,和大家一起功能促进分布式存储的健康发展,并为企业客户提供更灵活、高效、稳定的存储解决方案。
分享至:




更多精彩,请关注
杉岩数据官方微信
联系电话:400-838-3331
Copyright © 2014-2023 深圳市杉岩数据技术有限公司.
All rights reserved. 粤ICP备14100730号 法律声明/网站地图