
















大数据经过了多年的发展,以Hadoop生态为核心的大数据框架已经十分成熟,这个过程伴随着对存储需求的不断变化,从而演进出了数据湖的概念以及在数据湖存储方面的几个新需求特征:
如数据的分布组织与元数据的高效管理;存储和计算分离,大幅降低成本;数据全生命周期管理;多访问协议支持达到All in One的存储能力;具备数据的智能感知,能够更好地辅佐、支撑上层业务。
从业务需求和大数据发展的趋势来看,大数据存算分离是大势所趋。
当前Hadoop存储方案的局限
目前Hadoop生态的默认存储组件为HDFS,其本质上是存算一体的方案,存在很多不足,除了HDFS与计算应用组件的融合部署,导致整体集群扩容时计算与存储资源不平衡的问题之外,更主要在于HDFS自己的元数据架构存在瓶颈以及数据冗余效率的问题。总之,HDFS的发展适应不了当下快速增长的数据量对存储的需求。
Hadoop社区也支持采用S3A适配器的方式,将兼容S3协议的对象存储链接到Hadoop计算生态,实现存算分离。
杉岩数据的对象存储产品杉岩MOS完全兼容S3协议,可通过S3A适配器实现对Hadoop大数据平台的存储供应,并且杉岩MOS支持大比例EC、数据自动分层存储等特性。相比HDFS存储,在不降低可靠性的情况下,提供了高性价比的海量数据管理能力。但是S3A的方案仍然面临着一些问题:
对象存储自身KV形式的数据管理方式,在上层Hadoop计算框架使用的一些类POSIX语义的操作(比如目录的重命名,或对子目录的list操作)时成为了影响性能的关键因素,主要原因为对象存储自身没有目录的概念,上层计算侧的目录重命名和list操作,都会转换为时间复杂度极高的大量对象的“Copy+Delete”操作与遍历操作,在大规模作业时瓶颈效应尤其突出。
针对这些问题,S3A方案的业界头部用户与主要贡献厂商也在支持S3的场景下开发了各种S3A Committer,通过S3协议里的一些高级特性,巧妙地规避掉了如目录重命名的操作,但在流程上面的这些调整改造,也引入了如异常处理与任务回退的惩罚放大问题,以及第三方组件依赖等问题。因此,目前S3A的方案在私有云大数据处理环境中,更多地使用于小规模数据处理或备份归档的场景。
基于杉岩MOS的存储分离解决方案
面对以上HDFS与S3A的问题,杉岩数据推出了基于杉岩MOS海量对象存储的大数据存算分离场景的存储解决方案。除了提供业界通用的S3A方案,以解决普通大数据业务和大数据中的备份归档场景的需求之外,杉岩数据研发实现了兼容HDFS接口能力的高性能MOSFS数据湖文件网关,MOSFS核心组件分为以下几个部分:
1、元数据服务:即MOSFS-MDS,数据湖文件网关拥有独立的类文件系统的分布式元数据服务,具备横向扩展能力,同时也解决了HDFS NameNode在海量小文件场景下的元数据性能瓶颈问题。
2、数据部分:MOSFS的数据部分基于杉岩 MOS底层的对象存储,通过IO路径优化,抛弃了S3A通过S3协议网关(即下图中的RGW)访问底层数据的方式,实现了通过文件网关客户端直接与底层存储平台层(即下图中的RADOS)进行数据交互的能力,进一步提升了数据访问的效率与性能。
3、MOSFS客户端:即MOSFS-Client,实现了对HDFS接口协议完全兼容,可以保证应用层就像使用原生HDFS存储一样使用MOSFS。同时,为了解决存算分离后存储与计算之间的网络延迟问题,MOSFS 提供了客户端缓存能力,利用客户端的内存或SSD资源,加速数据的读取。
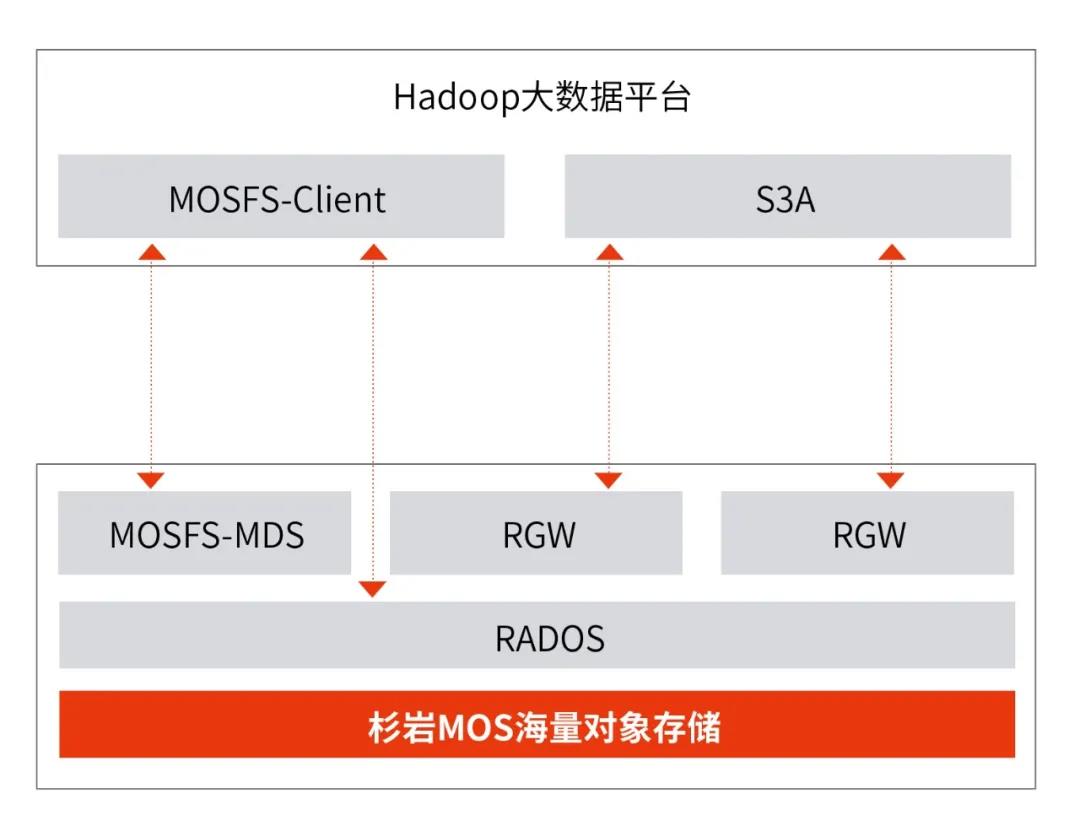
图1 杉岩MOS存算分离方案架构图
实际场景中,通过在计算平台部署我们提供的MOSFS-Hadoop.jar包与简单的配置,即可方便地实现Hadoop平台的组件与分离部署的存储交互。同时针对业界使用比较广泛的CDH平台,MOSFS也开发了配套的Parcel资源包,利用CDH自身的管理便捷地配置使用MOSFS提供的存储空间。
几种方案的性能对比
针对大数据的场景,我们使用相同的4节点CDH计算集群和杉岩MOS做了上文提及的HDFS/S3A/MOSFS三种方案的性能对比测试。为了体现存算一体与存算分离架构的测试环境公平性,存算一体时的HDFS存储与存算分离时所用的MOS存储,均使用相同的节点数和相同的数据盘。
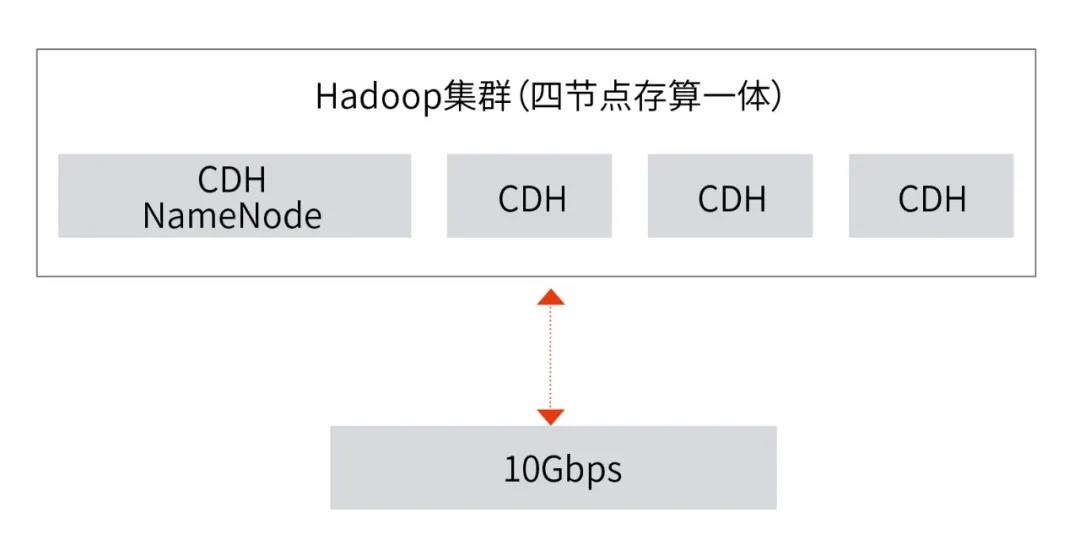
图2 HDFS存算一体测试环境
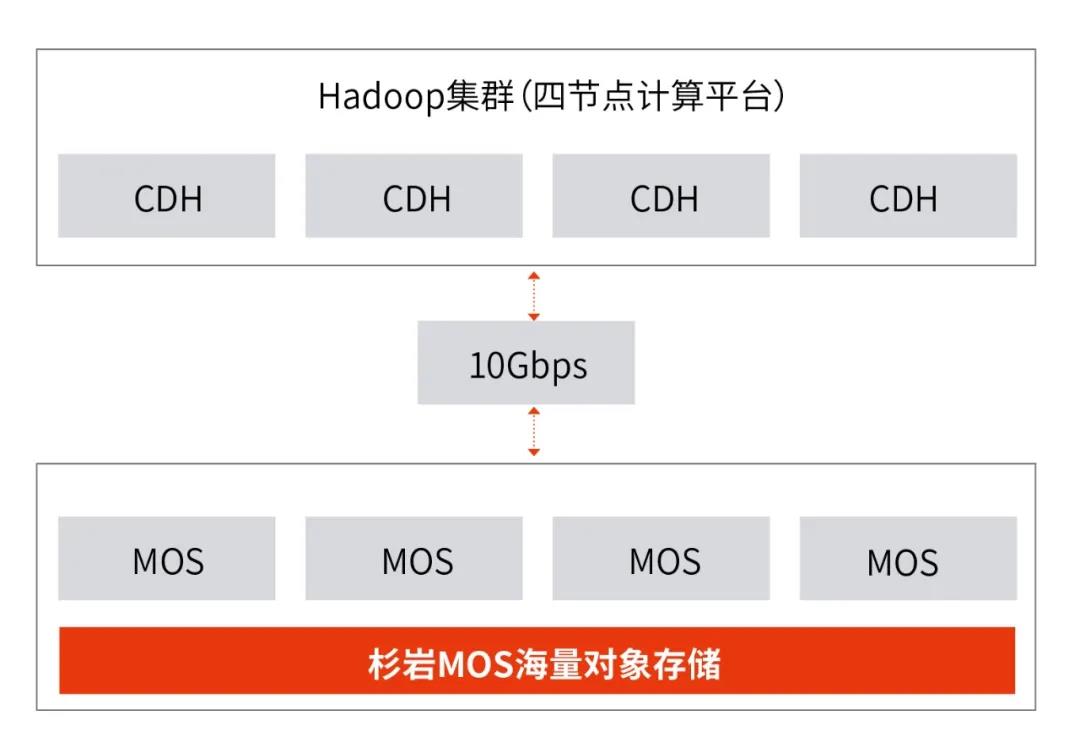
图3 S3A&MOSFS存算分离测试环境
1、TeraGen/TeraSort/TeraValidate测试
TeraGen/TeraSort/TeraValidate是Hadoop提供的测试HDFS文件系统的读写性能,及对MapReduce自动排序能力测试的标准测试用例,主要分为三步:
1)通过TeraGen生成排序的随机数据;
2)对输入数据执行TeraSort排序;
3)对排序的输出数据利用TeraValidate进行校验。
我们使用相同的Hadoop MapReduce配置执行100多亿条100Byte的数据,合计1TB数据规模的对应任务。
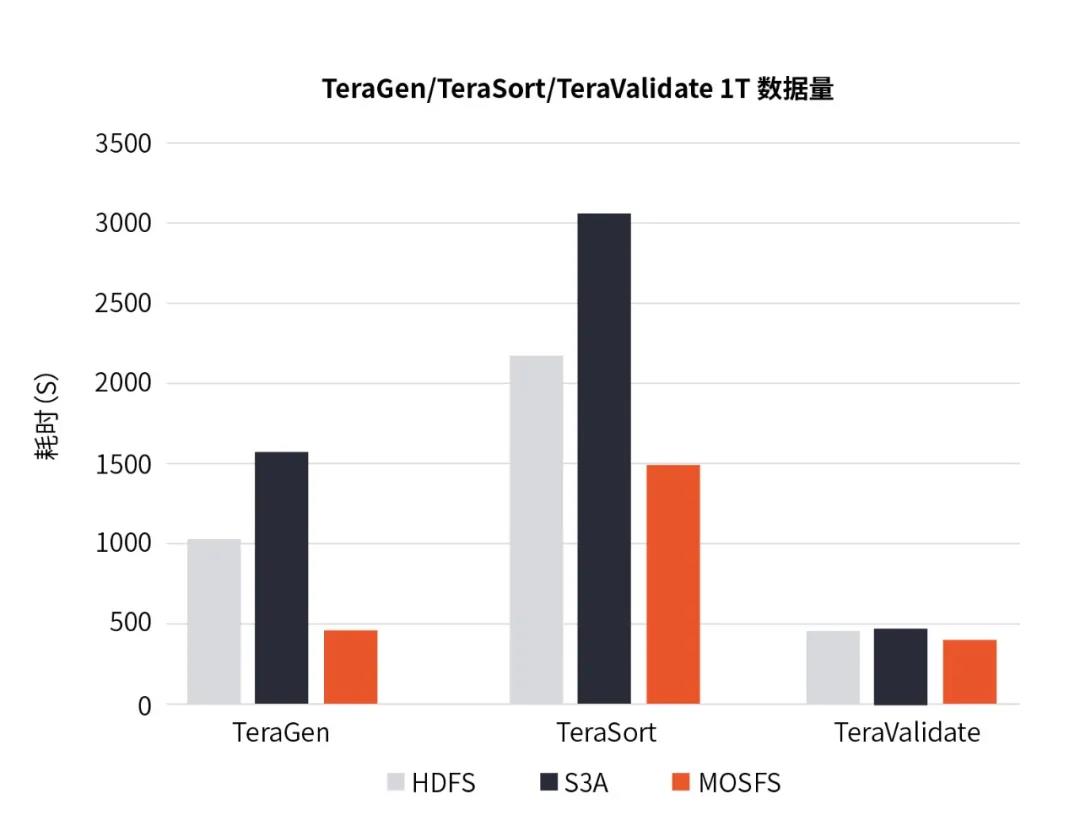
图4 TeraGen/TeraSort/TeraValidate测试数据对比
结果显示,MOSFS在TeraGen与TeraSort任务中执行效率明显高于HDFS与S3A方案。其中在相同的TeraGen任务上,HDFS耗时为MOSFS的2.31倍,S3A方案耗时为MOSFS的3.3倍;相同的TeraSort任务上,HDFS耗时为MOSFS的1.32倍,S3A方案耗时为MOSFS的1.56倍;在TeraValidate任务中计算的消耗比重大于数据访问的比重,所以三者的效率相当。
2、RandomTextWriter/WordCount测试
RandomTextWriter用来随机数据生成压力测试,且经典的单词计数WordCount 是CPU 算力压力测试的常用用例。其中,RandomTextWriter 使用Map & Reduce来运行分布式作业,每个任务生成一个大的未排序的随机单词序列(其中键为5-10个单词,值为20-100个单词),我们用它来模拟生成1TB数据的压力测试,然后对该1TB数据量进行WordCount任务统计单词计数测试。
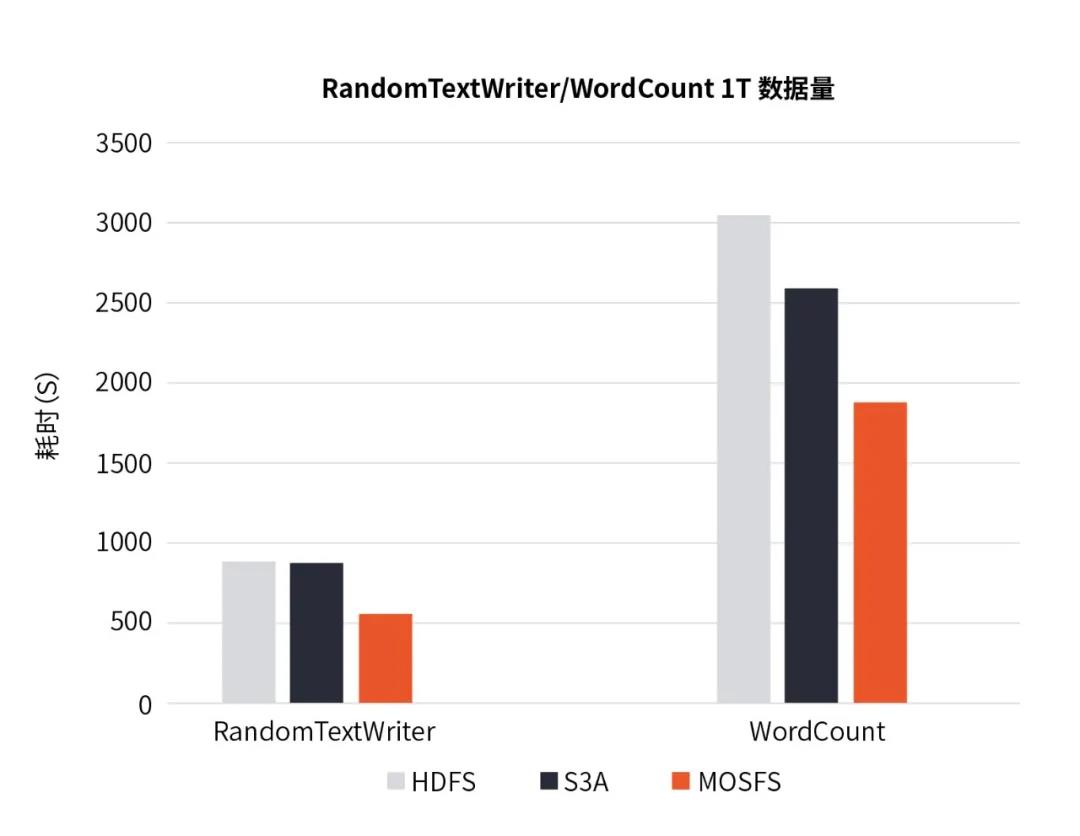
图5 RandomTextWriter/WordCount测试数据对比
结果显示,RandomTextWriter生成任务时,MOSFS对比HDFS和S3A方案具有明显的优势,HDFS与S3A方案的执行时间都约为MOSFS的1.9倍。对于WordCount在计算节点同等配置下,Reduce阶段执行效率大体一致,性能优化主要为Map读取数据阶段,WordCount整个任务耗时HDFS与S3A方案分别为MOSFS的1.7倍于1.2倍。
3、TestDFSIO测试
针对带宽型的读写,我们执行的是HDFS常用I/O性能评估工具TestDFSIO的测试,本次测试采用文件数1024个1GB大小文件共1T数据量的规模来进行读写测试对比,测试结果如下:
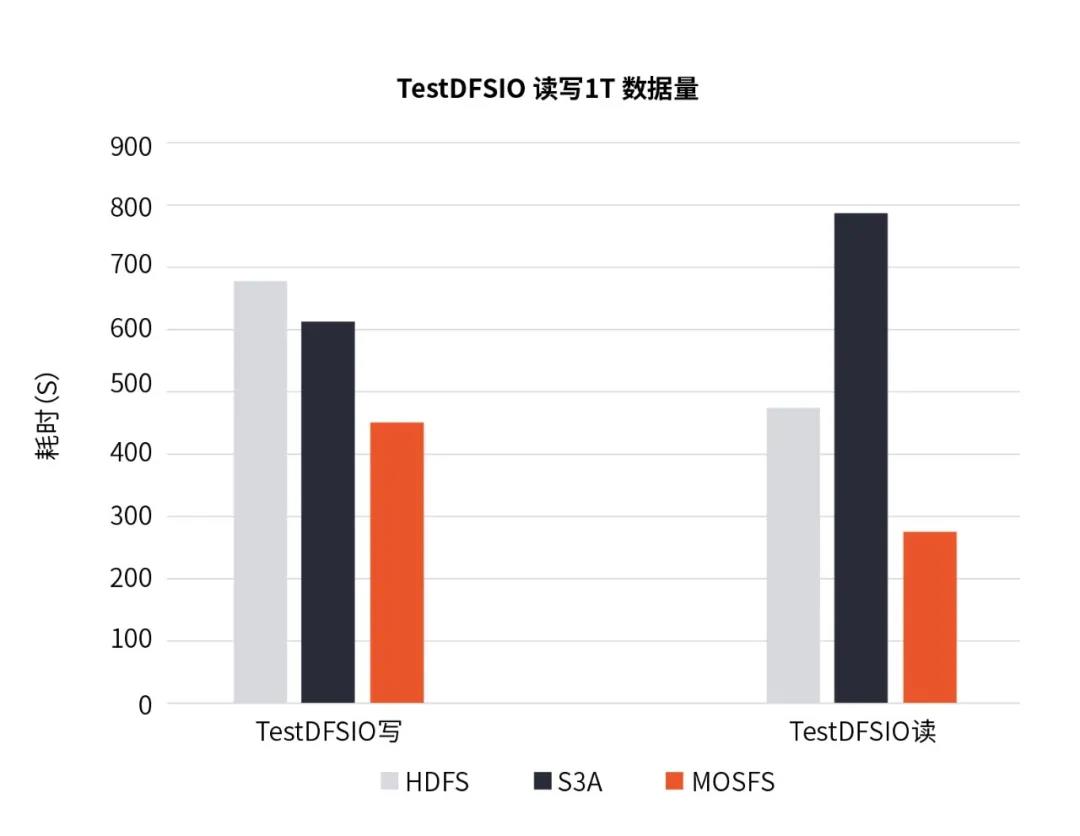
图6 TestDFSIO读写数据对比
结果显示,TestDFSIO读写时MOSFS的性能优于HDFS和S3A,HDFS写1T数据量执行的时间是MOSFS的1.5倍,S3A方案相同任务执行时间为MOSFS的1.3倍;且读该1T数据量时HDFS的耗时是MOSFS的1.69倍,S3A方案相同任务执行时间是MOSFS的1.4倍。
4、HBase性能测试
YCSB是雅虎开源的分布式性能测试工具,常用于测试NoSQL数据库的读写性能。我们使用 YCSB套件对HBase测试了1亿条数据规模的写入与读取测试,且YCSB使用多计算节点并发测试读写性能。
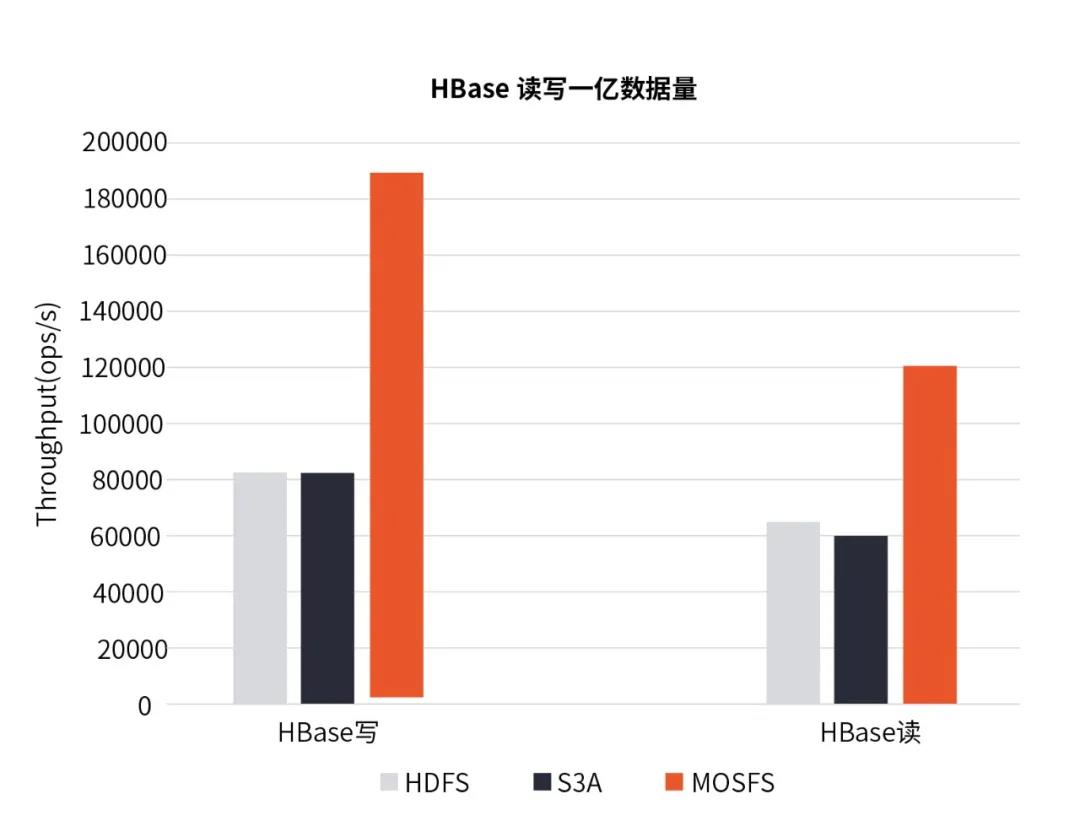
图7 HBase读写数据对比
结果显示,MOSFS在HBase小文件IO场景业务中,HBase写一亿数据量时的OPS统计MOSFS分别是HDFS与S3A的2.15倍与2.3倍,读该一亿数量时的OPS统计MOSFS分别是HDFS与S3A的1.77倍与1.92倍,即MOSFS在HBase业务模型下,读写性能明显优于HDFS与S3A方案。
总结
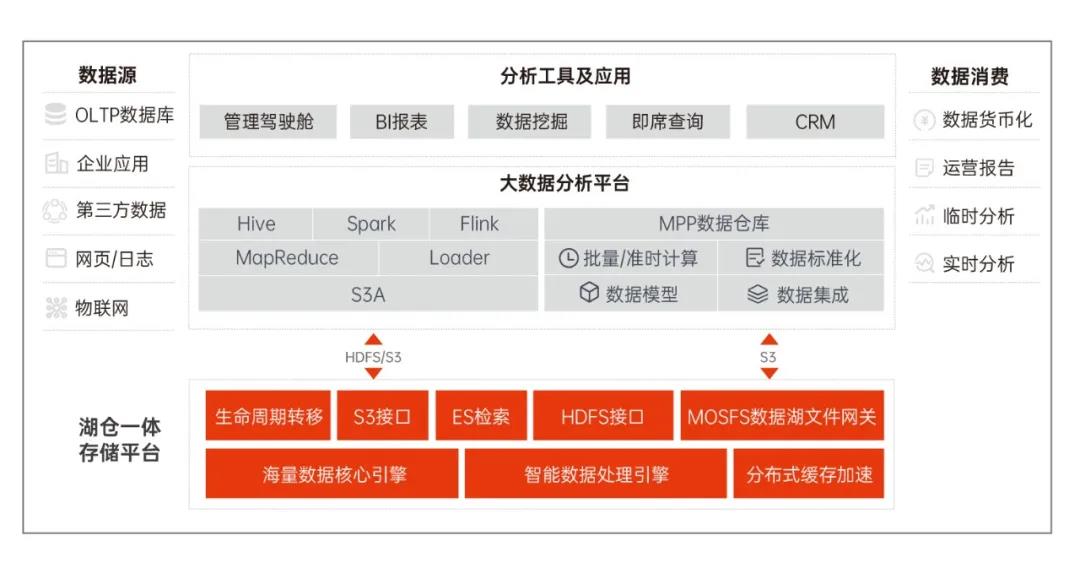
图8 杉岩湖仓一体解决方案
作为国内SDS的头部厂商,杉岩数据近年来深耕行业场景,尤其在应对海量数据爆炸式增长的条件下,潜心打磨分布式对象存储杉岩MOS。上述文章中的测试数据也体现出了数据湖文件网关MOSFS方案在Hadoop生态中的优势,与杉岩MOS自身的高性能EC纠删码、生命周期管理、智能处理引擎、ES检索等高级特性相结合,使基于杉岩MOS为基座的湖仓一体方案更加完善,为客户实现All in One的存储能力。





