



















几天前的那碗“加了Ceph的热干面”(回复关键词“热干面”获得)还记得吗?希望你记得。当然,如果你还记得bcache是如何让Ceph OSD快速入味的,那就更好了。如果你不记得,没关系,今天,我们将这道佳肴的菜谱倾情奉送,拿走,别谢。
本文作者:花瑞,杉岩数据高级研发工程师。
一 、Ceph中使用SSD部署混合式存储的两种方式
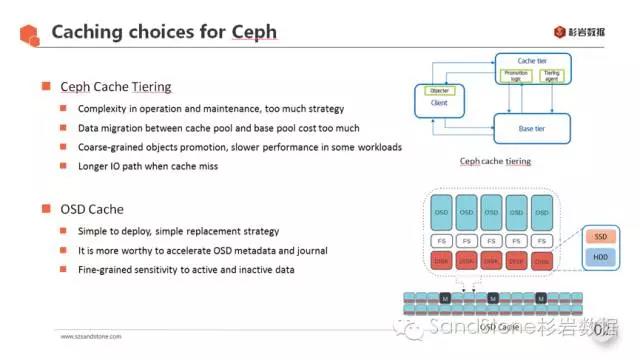
目前在使用Ceph中使用SSD的方式主要有两种:cache tiering与OSD cache,众所周知,Ceph的cache tiering机制目前还不成熟,策略比较复杂,IO路径较长,在有些IO场景下甚至还会导致性能下降,promotion的粒度较大也有较多的负面影响。所以在SSD的使用上,我们选择了给OSD所在块设备加速的方式。
二 、Linux块层SSD Cache方案的选择
在Linux内核块层,使用SSD给HDD块设备加速,目前较为成熟的方案有:flashcache,enhanceIO,dm-cache,bcache等。
2.1 特性对比
在这几种开源方案中,前三种的cache块索引算法都比较相近,都是基于hash索引,主存数据块到缓存块采用的是组相联的映射方式。下表以flashcache/enhanceIO为例,与bcache作了简单对比。
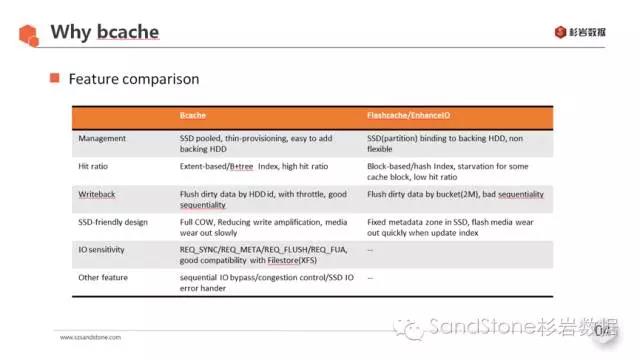
Bcache与其它几种方式最大的不同之处在于,它采用一棵相对标准的B+树作为索引,命中率会有很大提高,同时,它在架构设计上考虑了SSD本身的一些特性,在最大程度上发挥SSD性能的同时,也保护了SSD的寿命,也就是对SSD闪存介质的亲和性较好。
2.2 可管理性/可维护性对比
在可管理性/可维护性方面,bcache的优势在于可以将SSD资源池化,一块SSD可对应多块HDD,形成一个缓存池(如下图)。
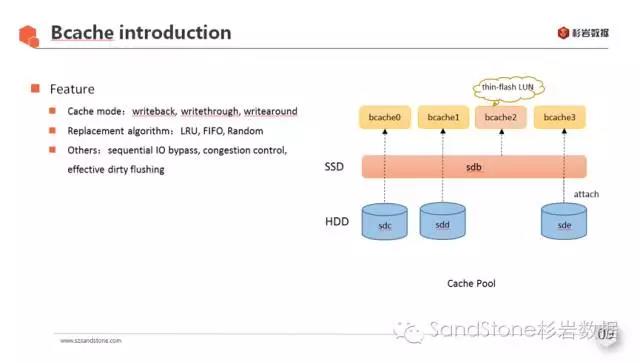
bcache还支持从缓存池中划出瘦分配的纯flash卷(thin-flash LUN)单独使用。
其它几种cache方案都必须将SSD(或分区)绑定到不同的HDD盘。
2.3 性能对比
bcache官方给出的性能对比数据,可参考以下链接:
http://www.accelcloud.com/2012/04/18/linux-flashcache-and-bcache-performance-testing/
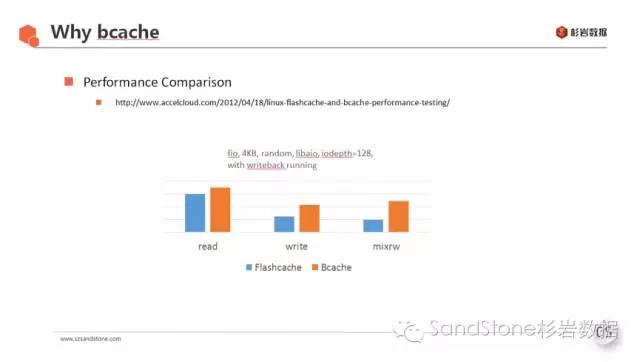
下图是杉岩在单机环境做的一个简单的测试,表现了在尽量能命中cache的情况下,二者的性能差异。集群环境下,性能差异接近单机版,在读写都能命中缓存的情况下,比较接近纯SSD集群的性能。
三 、Bcache内部技术简介
在Linux内核块层,使用SSD给HDD块设备加速,目前较为成熟的方案有:flashcache,enhanceIO,dm-cache,bcache等。
前面介绍了bcache在Ceph中为OSD加速的方案。现在我们来介绍一下bcache的内部逻辑,便于我们理解bcache性能优势的来源。
3.1 SSD上数据的Layout
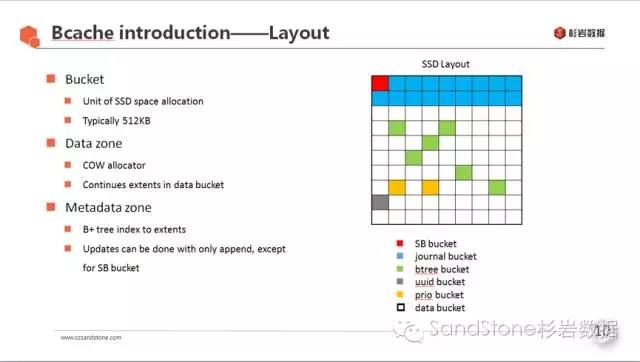
如图所示,bcache将SSD空间分成若干个bucket(典型值为512K,最好与SSD本身擦除块大小一致)。缓存数据与元数据都是按bucket来管理的:
分配器:COW式的空间分配,分配的单元是bucket,数据在bucket内部全部都是追加写入的,不会出现覆盖写,当有覆盖写时,会重定向到新的数据块。
元数据部分:B+树节点数据是最主要的元数据,也是COW式分配,对于B+树节点的修改,需要先分配新的节点,将新数据写入,再丢弃老的节点。
3.2 Bcache的索引
bcache用B+树来管理缓存数据与HDD上数据块的对应关系,B+树所索引的k-v结构在bcache中称为bkey。如下图所示:
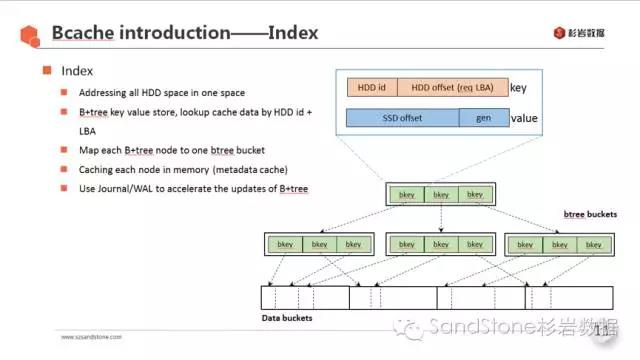
将一个缓存池中的多块HDD空间编址为一个地址空间
以HDD的id + IO请求的LBA为索引建立B+树
每个B+树的节点对应一个btree bucket,这个bucket里存的就是一个个的bkey
为每个btree bucket申请一块连续内存作为metadata缓存
利用Journal/WAL加速B+tree的修改, 写完journal以及内存中的B+tree节点缓存后写IO就可以返回了
3.3 垃圾回收
前面介绍bcache的分配器是以bucket为单位的COW式的分配,对与已经在SSD中的数据以及元数据,覆盖写时是写到新的空间中的,这样无效的旧数据就会在其所在的bucket内形成“空洞”,但是由于bcache空间回收的单位是bucket,因此需要一个异步的垃圾回收(GC)线程来实现对这些数据的标记与清理,并将含有较多无效数据的多个bucket压缩成一个bucket。

GC分为两个阶段:
1)元数据的GC:即B+树的GC,主要原理是遍历B+树,根据bkey信息标记出无效的缓存数据以及有效的缓存数据(包括脏缓存数据与干净的缓存数据),以及元数据。然后压缩清理元数据bucket。
2)缓存数据的GC:在bcache中被称为Move GC,主要原理是根据元数据GC阶段遍历B+树后生成的数据bucket的标记信息,找出含有较多无效数据的多个bucket,将其中的有效数据搬移到一个新分配的bucket中去,以便及时回收更多的bucket。
3.4 刷脏机制
使用bcache的writeback模式时,bcache会为缓存池中的每个HDD启动一个刷脏线程,负责将SSD中的脏数据刷到后端的HDD盘。
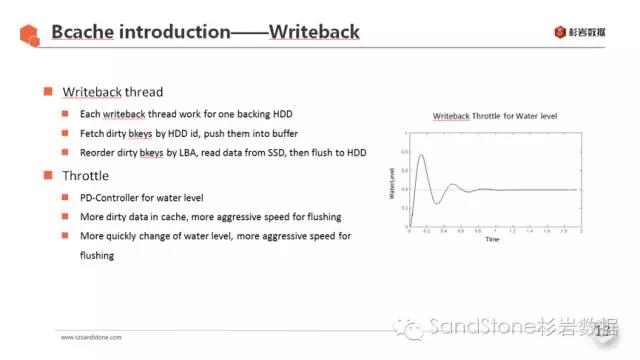
刷脏进程工作原理:
遍历B+树,找出指向本HDD上的脏数据块的所有bkey,按照bkey中包含的HDD上的LBA信息进行排序,这样根据排序后的bkey依次读出SSD上的数据块,写入HDD中,实现了顺序刷盘。
刷脏流控:
为了保证刷脏性能,同时尽量不影响业务IO的读写,bcache会根据脏数据的水位线来调节刷脏速率,具体是通过比例-微分控制器(PD-Controller)来实现的:当水位线越高,或者水位增高速度越快时,刷脏速度也越快。
四 、在生产环境中使用bcache的挑战
bcache的内部实现比较复杂,代码复杂度也比flashcache/enhanceIO等要高出不少,而且已经合入内核主线,在高版本内核(4.8及以上)上还是比较稳定可靠的,但是在Ceph系统中为OSD加速,还有一些问题需要解决:

4.1 功能问题
SSD&HDD不支持热插拔
将HDD从缓存池中卸载时需要等待脏数据全部刷完,时间较长
当HDD损坏时,SSD中相应的脏数据无法清除,造成空间浪费
Thin-flash卷在系统重启后无法恢复
4.2 性能问题
当上层的大量随机写IO充满缓存空间后,须等待脏数据全部刷完才能继续为写IO提供缓存
GC线程运行时会造成业务IO的波动
bcache元数据缓存对内存消耗较大,当系统内存不足时会导致大量元数据无法缓存,需要从SSD上读取,影响性能
五 、杉岩的具体实践
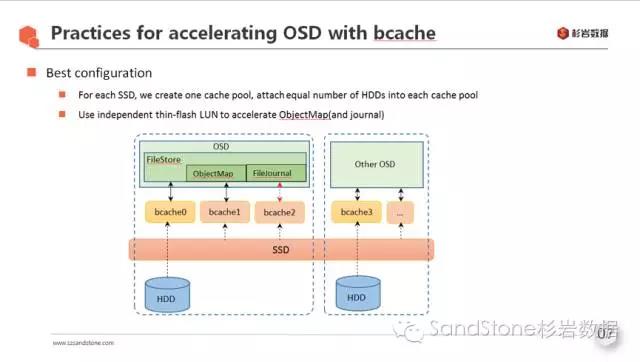
杉岩在使用bcache加速ceph OSD时,采取如上图所示的方式:
为每块SSD创建一个缓存池, 将相等数量的HDD attach到每个缓存池
从每个缓存池创建一个thin-flash卷将每个OSD的OMAP目录独立出来放入其中
Journal可以独立放到一个SSD, 也可以再从缓存池创建出若干thin-flash卷用于写Journal
杉岩数据通过大量测试及分析使得bcache在Ceph的生产环境上得以稳定运行,既最大限度地发挥了SSD的性能,同时,也提升了SSD的使用寿命,节省用户投资,为客户提供了更具性价比的混合存储方案。限于篇幅问题,这里仅仅列出了一些具体的解决思路,具体实现方法,可在微信后台留言与我们进行交流(我们会继续努力,争取尽快开通评论功能)。





